Unlocking asynchronicity in continuous batching

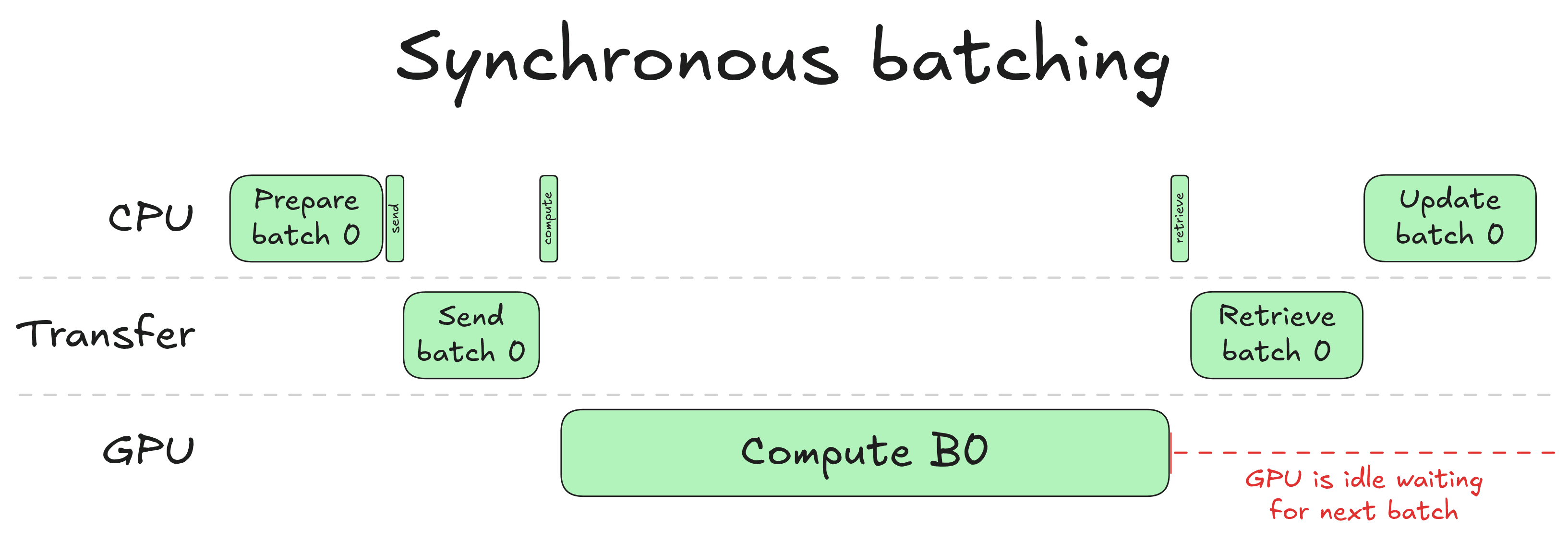
Unlocking asynchronicity in continuous batching TL;DR: we explain how to separate CPU and GPU workloads to get a massive performance boost for inference. This is the second post in a series on efficient LLM inference. The first post covered continuous batching from first principles. It introduces some concepts we build upon: KV cache, FlashAttention, attention masks, etc. An H200 costs around $5 an hour on Inference Endpoints. That's cheap for an hour, but use it for a day and you are already paying $120. If this is the case, you want your GPU to be used to its fullest. We have seen that Continuous Batching improves GPU utilization by scheduling tightly packed batches, so no compute is wasted on padding. But there is a second source of waste that continuous batching does not address: by default, it is synchronous. This means the CPU and GPU take turns: while the GPU computes, the CPU waits. And while the CPU prepares the next batch, the GPU waits. In a loop running hundreds of steps per second, those idle gaps add up, and as we will show, they can account for nearly a quarter of total runtime. To ensure the GPU is busy computing 100% of the time, we need to get rid of those gaps. To achieve this, we can use asynchronous batching: we are going to disentangle CPU batch preparation from GPU batch compute, so both can run in parallel and we always have a productive GPU 🔥 Synchronous batching This is how naive synchronous batching works: When the CPU prepares a new batch, it selects which requests to include, updates the KV cache table, evicts requests that finished in the previous runs, and admits new ones to fill the freed space. Once that is done, it transfers the prepared inputs to the GPU. The GPU runs its forward pass and samples (i.e. chooses) a new token for each request. The results come back to the CPU, so it knows what token each request just produced, then the whole cycle repeats again. Notice the red annotation on the right: after the GPU finishes computing, it goes idle. The next batch cannot start until the CPU has gone through its update step: sampling the output tokens, updating request states, re-scheduling the batch. This is the core inefficiency of synchronous batching: the CPU and GPU take turns. While the GPU is computing, the CPU is idle. While the CPU is updating, the GPU is idle. In no circumstances are they both doing useful work at the same time. For a single forward pass this might seem like a small price to pay, but in a continuous batching loop running hundreds of steps per second, these idle gaps accumulate into real throughput loss. To showcase this, we profile the time spent on CPU and GPU when generating 8K tokens with a batch size of 32 using an 8B model: If you want to produce the same kind of graph, you can instrument the continuous…