vLLM V0 to V1: Correctness Before Corrections in RL

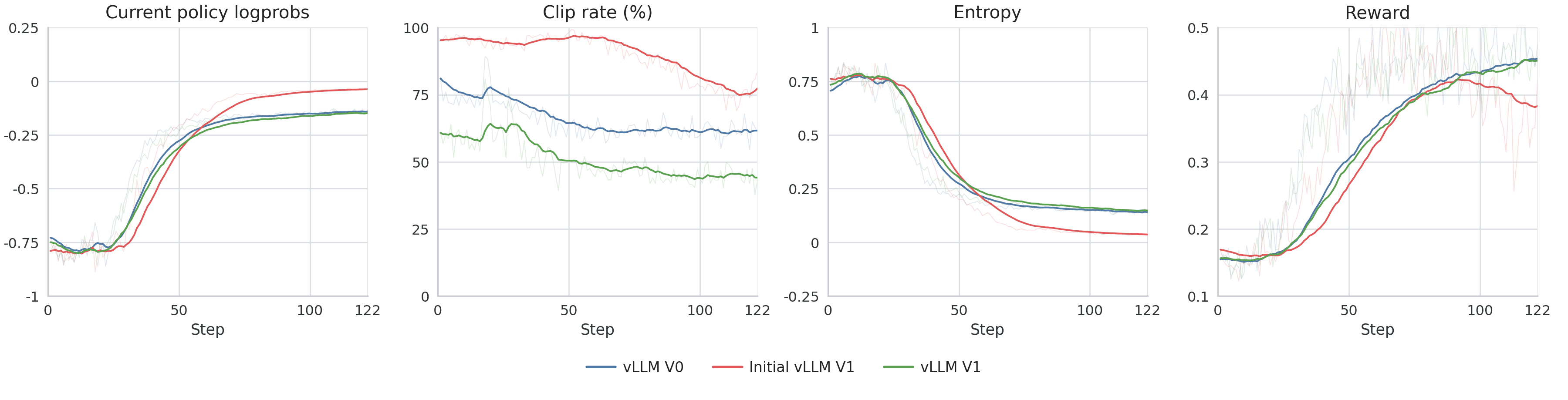
vLLM V0 to V1: Correctness Before Corrections in RL TL;DR. vLLM V1 matched our vLLM V0 reference after we fixed four things: processed rollout logprobs, V1-specific runtime defaults, the inflight weight-update path, and the fp32 lm_head used for the final projection. We fixed the backend behavior before changing the RL objective. The reference run used vLLM 0.8.5 ; the V1 runs used vLLM 0.18.1 . Figure 1 shows the final result. The red run is the initial V1 attempt, and the green run is the final V1 run after the fixes described below. Migration Objective vLLM V1 is a substantial rewrite of the V0 engine. Our migration target was therefore deliberately narrow: - verify that V1 returned rollout logprobs in the form the trainer expected - rerun the same workload against the V0 reference - evaluate objective-level changes only after backend parity was restored The first visible symptoms appeared in: clamp_log_ratio_new_old_indicator kl_new_old entropy reward Those metrics came from a GSPO training run, the objective used for this experiment. The same class of mismatch can surface in PPO, GRPO, or any online RL system that treats rollout-side logprobs as part of the optimization target. The initial V1 run showed the problem clearly. The trainer-side logprobs and reward moved away from the V0 reference early in training. The same pattern appears in the trainer metrics. Clip rate is the easiest signal to read in the initial comparison. Failure Modes We separated the possible causes into three layers: - Semantic mismatch: the backend returns logprobs with different meaning relative to what the trainer expects. - Inference-path mismatch: the backend uses different runtime defaults for caching, scheduling, or request handling, so the same prompts follow a different execution path. - Objective mismatch: the RL objective needs correction for the amount of staleness or backend mismatch that remains. We initially suspected the third category too early. The useful diagnosis came from treating the first two as backend behavior problems and ruling them out first. V1 Backend Fixes Logprob Semantics The first issue was semantic. vLLM V1 returns logprobs from the raw model outputs by default, before logits post-processing such as temperature scaling, penalties, and top-k/top-p filtering. PipelineRL expected logprobs from the processed distribution used by the sampler. The required setting was: logprobs-mode=processed_logprobs This removed the obvious mean offset in rollout logprobs. The training curves still showed a gap relative to the known-good reference, so the next issue had to be in the inference path. The policy-ratio plot shows this directly. Once processed_logprobs is on for V1, the mean policy ratio stays centered extremely close to 1.0 across all three runs. That establishes the mean-bias fix. The remaining mismatch shows up in clip rate, KL, entropy, and downstream training behavior. Runtime Defaults The early V1 run mixed the engine version with V1 runtime defaults: - prefix caching, left unset in the early run so the vLLM 0.18.1 default applied - async scheduling, left unset in the early run so the vLLM 0.18.1 default applied - an…