Organizing Agents’ memory at scale: Namespace design patterns in AgentCore Memory
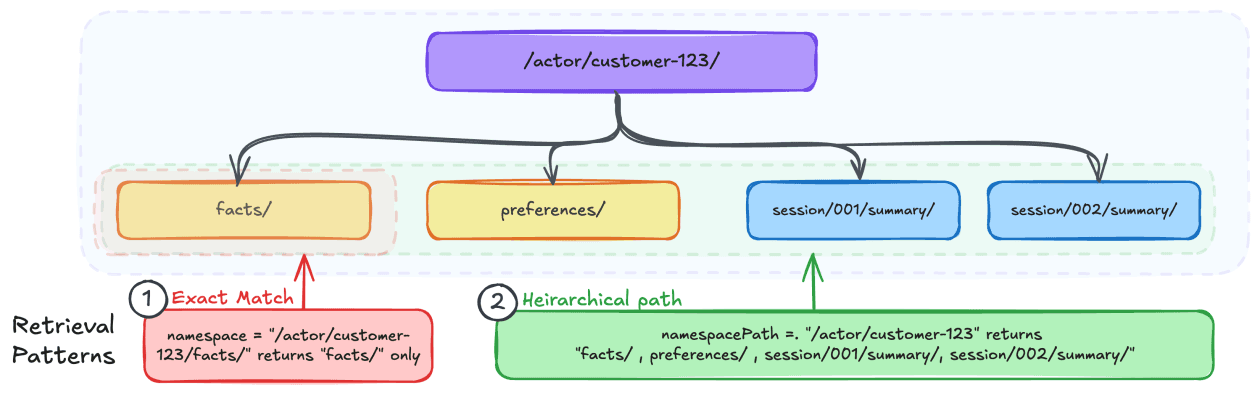
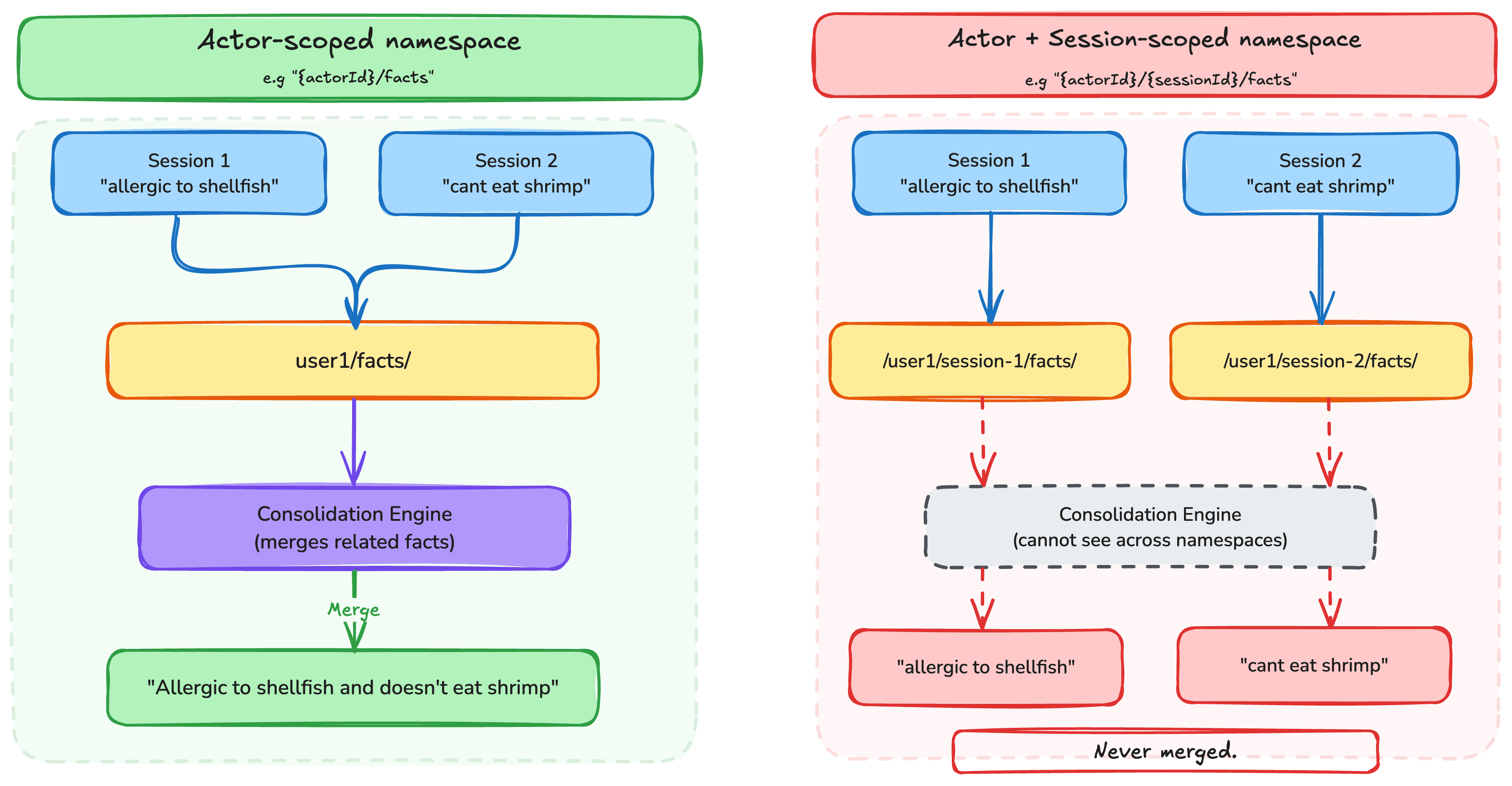
Artificial Intelligence Organizing Agents’ memory at scale: Namespace design patterns in AgentCore Memory When building AI agents, developers struggle with organizing memory across sessions, which leads to irrelevant context retrieval and security vulnerabilities. AI agents that remember context across sessions need more than only storage. They need organized, retrievable, and secure memory. In Amazon Bedrock AgentCore Memory, namespaces determine how long-term memory records are organized, retrieved, and who can access them. Getting the namespace design right is essential to building an effective memory system. In this post, you will learn how to design namespace hierarchies, choose the right retrieval patterns, and implement AWS Identity and Access Management (IAM)-based access control for AgentCore Memory. If you’re new to AgentCore Memory, we recommend reading our introductory blog post first: Amazon Bedrock AgentCore Memory: Building context-aware agents. What are namespaces? Namespaces are hierarchical paths that organize long-term memory records within an AgentCore Memory resource. Think of them like directory paths in a file system. They provide logical structure, enable scoped retrieval, and support access control. When AgentCore Memory extracts long-term memory records from your conversations, each memory record is stored under a namespace. For example, a user’s preferences might live under /actor/customer-123/preferences/ , while their session summaries might be stored at /actor/customer-123/session/session-789/summary/ . With this structure, you can retrieve memory records at exactly the right level of granularity. If you’ve worked with partition keys in Amazon DynamoDB or folder structures in Amazon Simple Storage Service (Amazon S3), the mental model transfers well. Just as you think through access patterns before choosing a partition key or designing your S3 folder hierarchy, you should think through your retrieval patterns before designing your namespace structure. Determine: - Who needs to access these memories: A single user? All users of an agent? - Granularity of retrieval you need: Is it per-session summaries? Cross-session preferences? - Isolation boundaries that matter: Should one user’s memories ever be visible to another? Agent-scoped memories? The main difference from a partition key is that namespaces support hierarchical retrieval in addition to exact match. You can query at each level of the hierarchy, not only at the leaf level. You can use a well-designed namespace to retrieve memories scoped to a single session, a single user across sessions, or a broader grouping, from the same memory resource. Namespaces are logical groupings within the same underlying storage. They provide organizational structure and access control, but long-term memory records across different namespaces co-exist within the same memory resource. Your hierarchy is your primary tool for organizing data for effective retrieval patterns. Namespace templates and resolution When creating a memory resource, you define namespace templates using the namespaceTemplate field within each strategy configuration. Templates support three pre-defined variables: {actorId} – resolves to the actor identifier from the events being processed{sessionId} – resolves to the session identifier from the events{memoryStrategyId} – resolves to the strategy identifier Here’s an example of creating a memory resource with namespace templates: When events arrive for actorId=customer-456 in sessionId=session-789 , the resolved…