Manufacturing intelligence with Amazon Nova Multimodal Embeddings

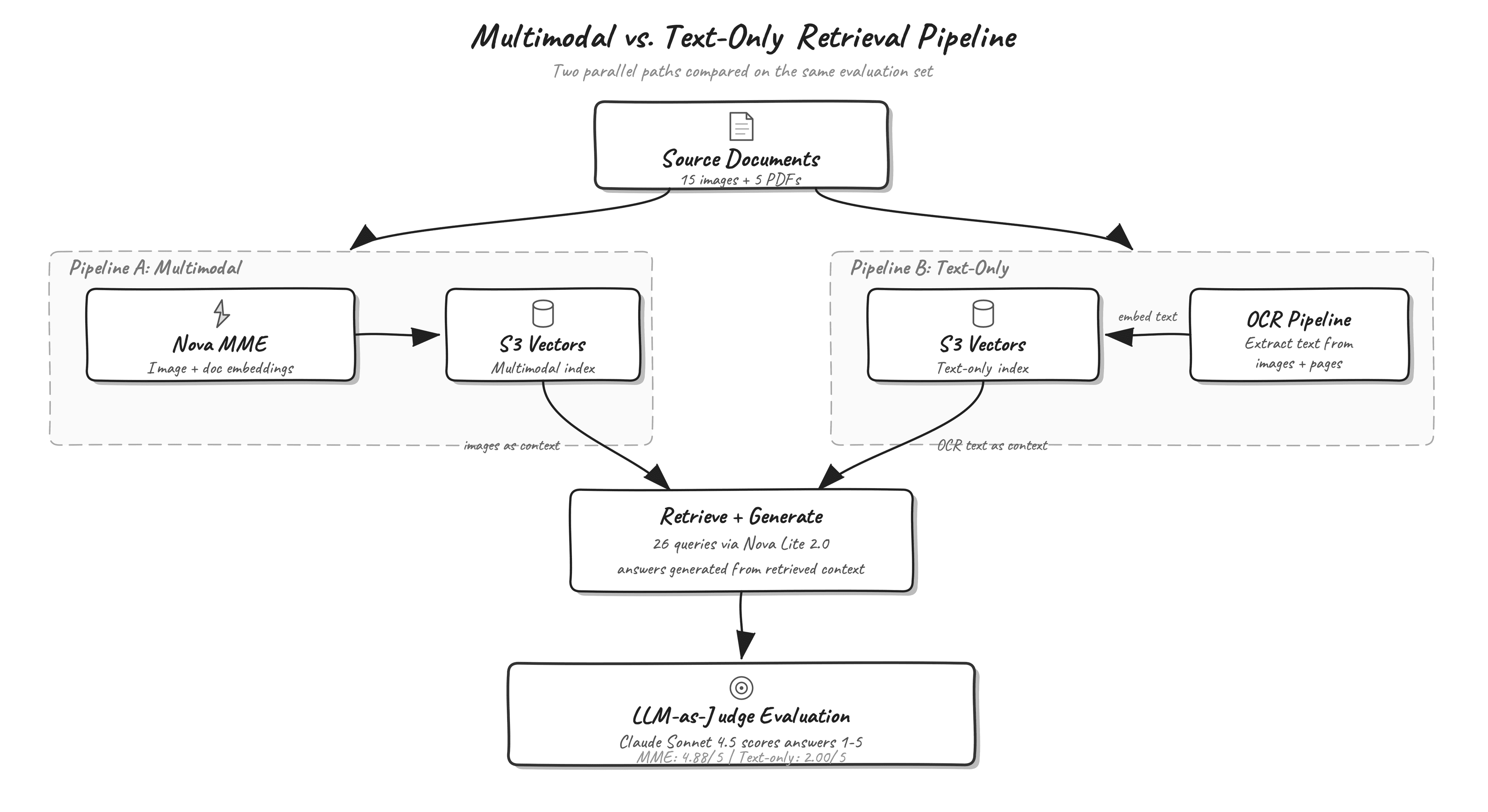
Artificial Intelligence Manufacturing intelligence with Amazon Nova Multimodal Embeddings If you work in aerospace, automotive, or heavy industry manufacturing, your organization likely maintains vast repositories of technical documents. These documents combine written specifications with engineering diagrams, CAD drawings, inspection photographs, thermal analysis plots, and fatigue curves. A text query about maximum wall temperature at the nozzle throat might have its answer locked inside a thermal contour plot rather than written prose. Text-only retrieval systems can’t surface that information because they don’t see the image content. Amazon Nova Multimodal Embeddings addresses this gap by mapping text, images, and document pages into a shared vector space. A text query can retrieve an engineering diagram, and an image query can retrieve a written specification, because both modalities share the same coordinate system. In this post, we build a multimodal retrieval system for aerospace manufacturing documents using Amazon Nova Multimodal Embeddings on Amazon Bedrock and Amazon S3 Vectors. We evaluate the system on 26 manufacturing queries and compare generation quality between a text-only pipeline and the multimodal pipeline. Why multimodal retrieval matters for manufacturing Most manufacturing documents combine text, diagrams, and images. A single work order might contain written assembly procedures alongside annotated photographs of completed steps. An inspection report pairs pass/fail measurements with radiographic images of weld joints. A material certification includes both tabular mechanical properties and S-N fatigue curves that an engineer must reference during design review. Consider a few concrete examples of visual information from the dataset used in this post: A torque specification table is depicted inside an engineering drawing rather than stored as standalone text. A color-coded thermal contour plot is used to visualize peak temperatures across a rocket engine nozzle. A manufacturing process flow chart labels quality hold points visually with decision diamonds and color-coded gates, and the associated cycle times appear as annotations on the diagram itself. Text-only retrieval systems handle these documents by extracting text through OCR, then embedding and indexing the extracted strings. This works when answers appear in the written portions of a document, but text-only systems miss the spatial relationships in diagrams, the visual patterns in inspection images, and the quantitative information encoded in plots and charts. When you make a search for the type of bearings used in the turbopump, the answer might appear as a labeled callout on a cross-section diagram that OCR either misreads or strips of its spatial context. Multimodal embeddings take a different approach. Instead of converting images to text and then embedding the text, the model processes the image directly and produces a vector in the same space as text embeddings. A text query about turbopump bearings can match against the cross-section diagram in our dataset based on visual understanding, not just whatever text OCR managed to extract. Amazon Nova Multimodal Embeddings overview Amazon Nova Multimodal Embeddings is available in Amazon Bedrock and generates embeddings for text, images, and multipage documents. Text, image, and document modalities project into a single shared vector space, which means you can…