How Amazon Finance streamlines regulatory inquiries by using generative AI on AWS
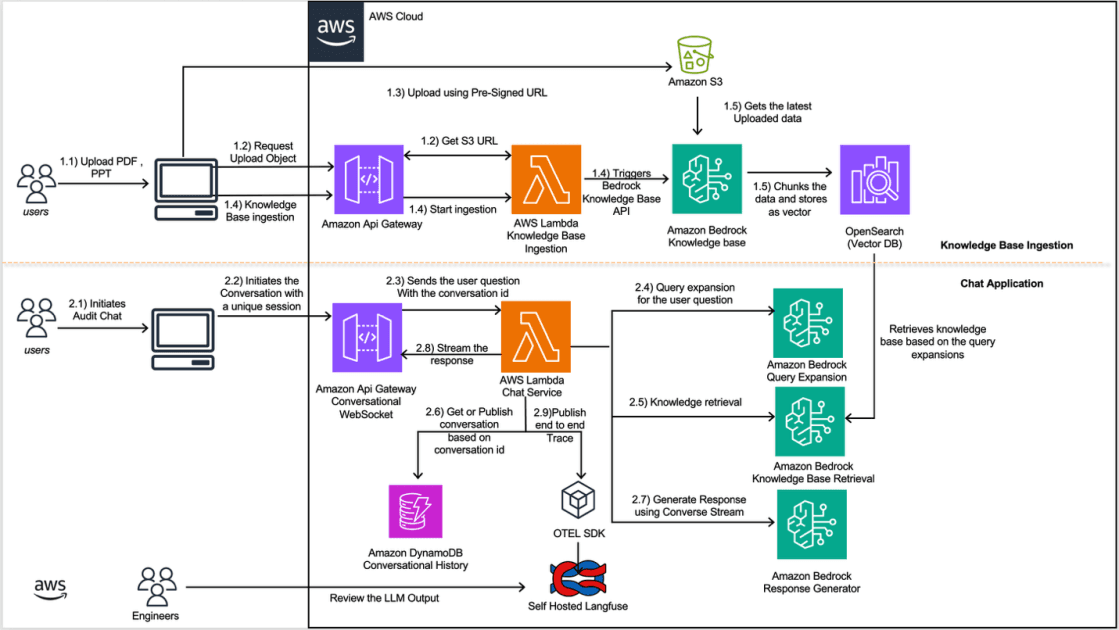
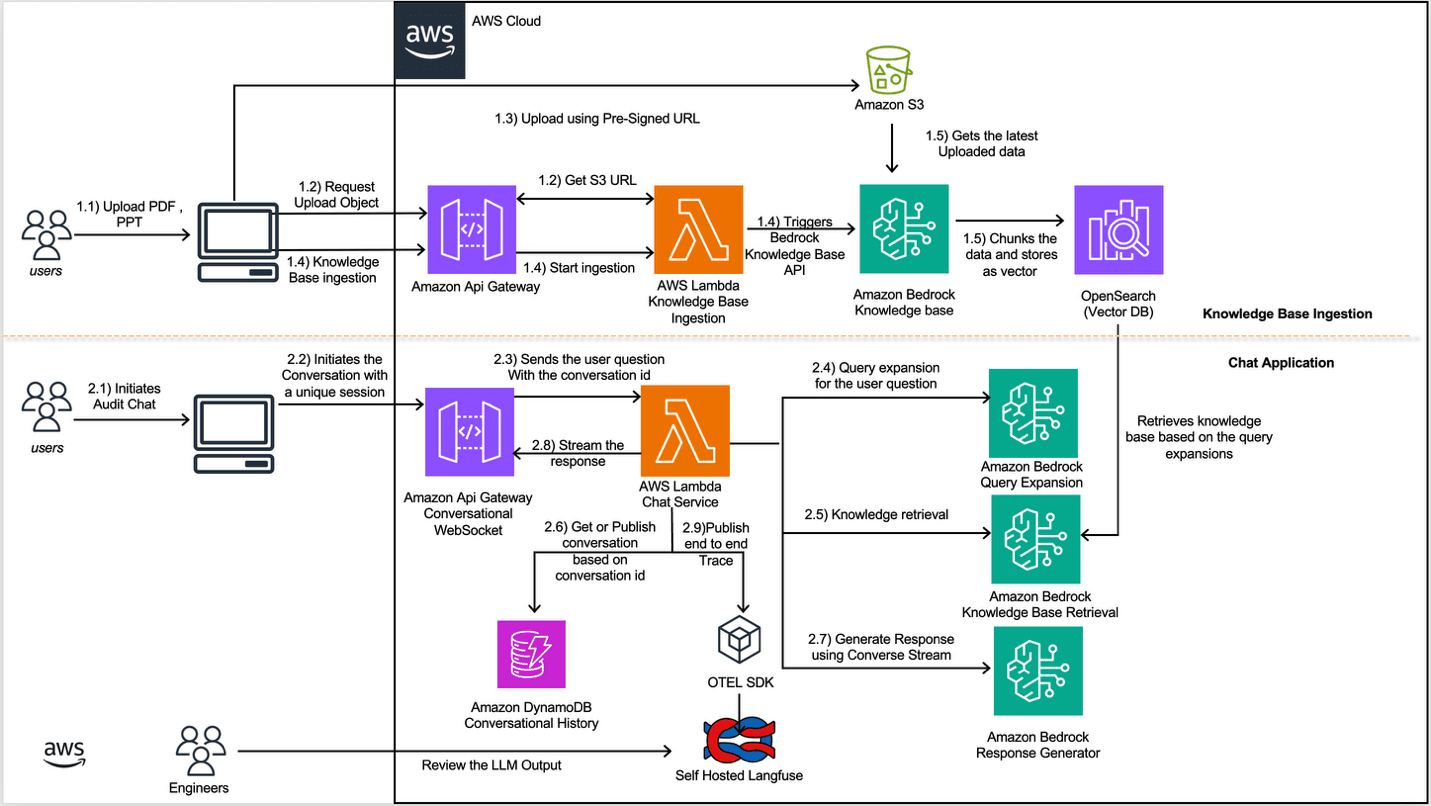
Artificial Intelligence How Amazon Finance streamlines regulatory inquiries by using generative AI on AWS Amazon’s Finance Technology (FinTech) teams build and operate systems for Amazon teams to manage regulatory inquiries in compliance with different jurisdictions. These teams process regulatory inquiries from authorities, each presenting different requirements, document formats, and complexity levels. Processing these regulatory inquiries involves reviewing documentation, extracting relevant information, retrieving supporting data from multiple systems within Amazon’s infrastructure, and compiling responses within regulatory timeframes. As inquiry frequency and business complexity grew, Amazon needed a more scalable approach. In this post, we demonstrate how Amazon FinTech teams are using Amazon Bedrock and other AWS services to build a scalable AI application to transform how regulatory inquiries are handled. Each team using this solution creates and maintains its own dedicated knowledge base, populated with that team’s specific documents and reference materials. Challenges The scale and complexity of managing regulatory inquiries presented several interconnected challenges: Knowledge fragmentation and retrieval complexity Regulatory inquiries require synthesizing information from thousands of historical documents. These documents exist in various formats (PDF, PPT, Word, CSV) and contain domain-specific terminology. Teams needed a way to quickly locate relevant precedents and supporting information across this vast corpus while maintaining accuracy and regulatory compliance. Conversational context and state management Regulatory inquiries require multi-turn conversations where context from earlier interactions is essential for generating accurate responses. Maintaining conversational state across sessions and tracking response evolution as team members refine answers through iterative interactions presents significant complexity. Observability and continuous improvement With generative AI systems, understanding why a particular response was generated is as important as the response itself. Teams required comprehensive visibility into the retrieval process, model decisions, and user interactions to identify areas for improvement and maintain compliance with responsible AI principles. For example, teams must detect when the model hallucinates information that isn’t present in source documents, or catch when the system retrieves outdated compliance guidelines that could lead to regulatory violations. AI systems experience accuracy drift over time as models, prompts, and the document corpus change, requiring continuous monitoring. Solution overview To address these challenges, Amazon FinTech team built an intelligent regulatory response automation system using Amazon Bedrock, AWS Lambda, and supporting AWS services. The solution implements Retrieval Augmented Generation (RAG) with Amazon Bedrock Knowledge Bases and Amazon OpenSearch Serverless for vector storage, enabling information retrieval from thousands of historical documents. Real-time chat interactions powered by Claude Sonnet 4.5 through the Converse Stream API, combined with Amazon DynamoDB for conversation history management, provide contextually-aware multi-turn conversations. Comprehensive observability through OpenTelemetry and self-hosted Langfuse ensures continuous monitoring and improvement of the AI system’s performance. The system doesn’t cache large language model (LLM) responses or intermediate results because regulatory inquiries are highly contextual and are prone to a low cache hit rate. The following diagram shows how you can use Amazon Bedrock Knowledge Bases in a workflow, alongside Converse API and other tools, to provide necessary information for regulatory inquiries: Knowledge base ingestion flow The knowledge base ingestion flow…