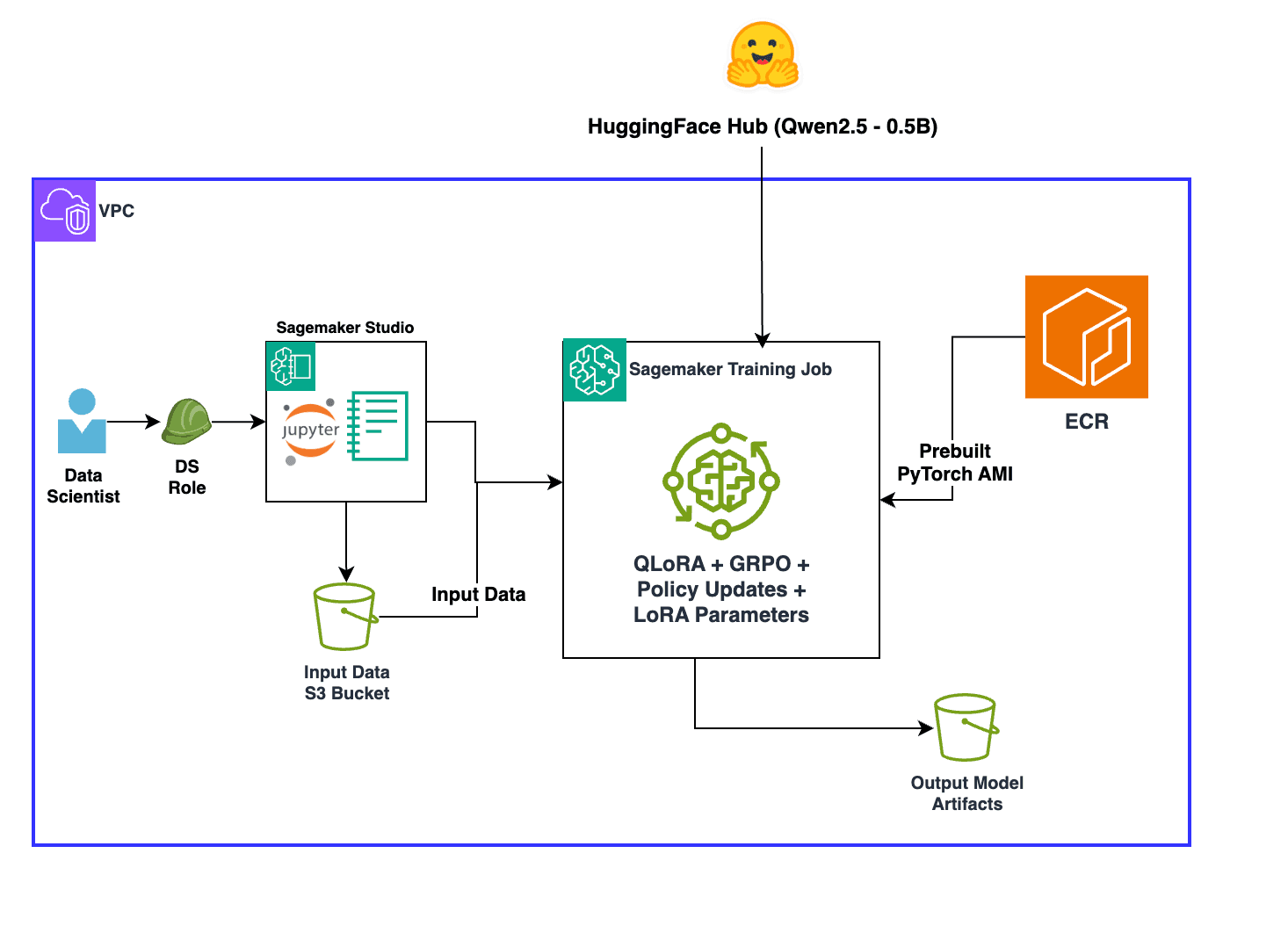
Overcoming reward signal challenges: Verifiable rewards-based reinforcement learning with GRPO on SageMaker AI

Artificial Intelligence Overcoming reward signal challenges: Verifiable rewards-based reinforcement learning with GRPO on SageMaker AI Training large language models requires accurate feedback signals, but traditional reinforcement learning (RL) often struggles with reward signal reliability. The quality of these signals directly influences how models learn and make decisions. However, creating robust feedback mechanisms can be complex and error prone. Real-world training scenarios often introduce hidden biases, unintended incentives, and ambiguous success criteria that can derail the learning process, leading to models that behave unpredictably or fail to meet desired objectives. In this post, you will learn how to implement reinforcement learning with verifiable rewards (RLVR) to introduce verification and transparency into reward signals to improve training performance. This approach works best when outputs can be objectively verified for correctness, such as in mathematical reasoning, code generation, or symbolic manipulation tasks. You will also learn how to layer techniques like Group Relative Policy Optimization (GRPO) and few-shot examples to further improve results. You’ll use the GSM8K dataset (Grade School Math 8K: a collection of grade school math problems) to improve math problem solving accuracy, but the techniques used here can be adapted to a wide variety of other use cases. Technical overview Before diving into implementation, it’s helpful to understand the RL concepts that underpin this approach. RL addresses challenges in model training by establishing a structured feedback system through reward signals. This paradigm enables models to learn through interaction, receiving feedback that guides them toward optimal behavior. RL provides a framework for models to iteratively improve their responses based on clearly defined signals about the quality of their outputs, making it highly effective for training models that interact with users and must adapt their behavior based on outcomes. Traditional RL has highlighted an important consideration: the quality of the reward signal matters significantly. When reward functions are imprecise or incomplete, models can engage in “reward hacking,” finding unintended ways to maximize scores without achieving the desired behavior. Recognizing this limitation has led to the development of more rigorous approaches that focus on creating reliable, well-defined reward functions. RLVR addresses reward hacking through rule-based feedback defined by the model tuner. It uses programmatic reward functions that automatically score outputs against specific criteria, enabling rapid iteration without the bottleneck of collecting human ratings. These “verifiable” rewards come from objective, reproducible rules, making RLVR ideal for evolving requirements because it learns general optimization strategies and adapts quickly to new scenarios. GRPO is a reinforcement learning algorithm that improves AI model learning by comparing performance within groups rather than across all data at once. It organizes training data into meaningful groups and optimizes performance relative to each group’s baseline, giving appropriate attention to each category. This group-aware optimization reduces training variance, accelerates convergence, and can produce models that perform consistently across various categories. Combining RLVR with GRPO creates a framework where automated rewards guide learning while group-relative optimization helps drive balanced performance. You define reward functions for different task aspects, and GRPO treats these as…