Automate schema generation for intelligent document processing

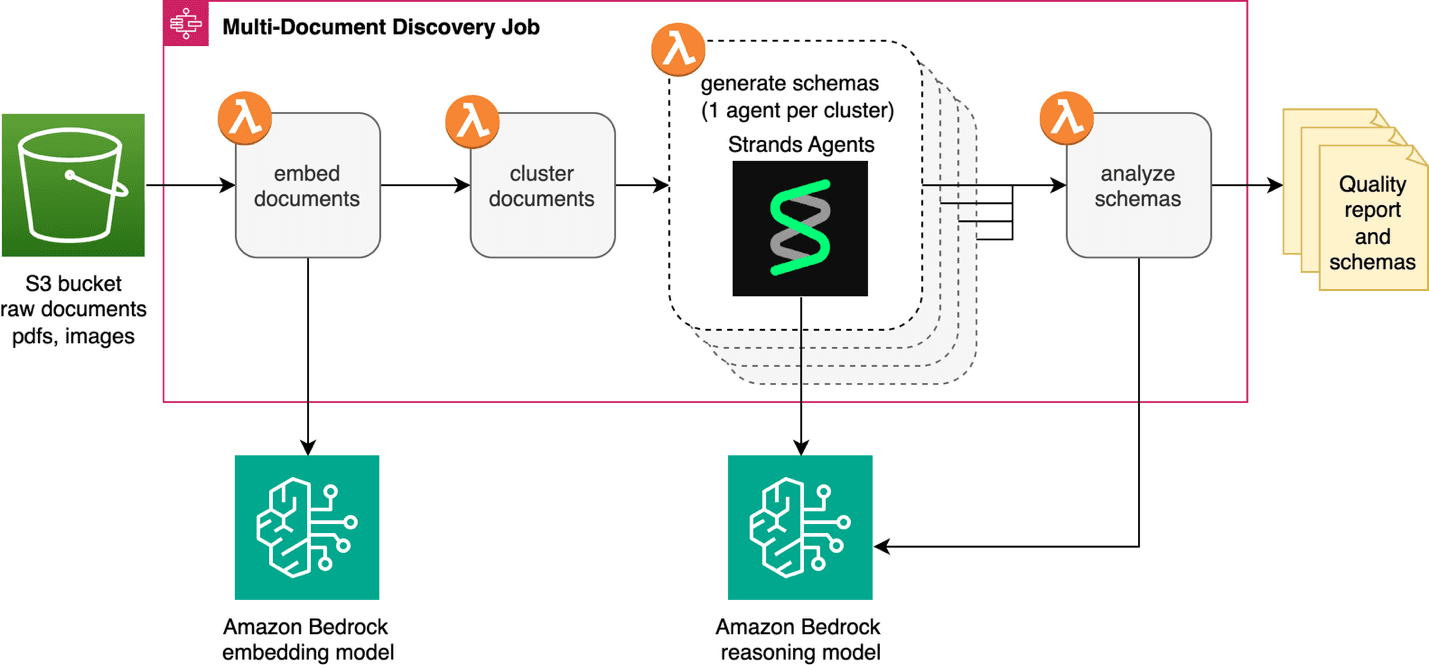
Artificial Intelligence Automate schema generation for intelligent document processing Before you can extract information from documents using intelligent document processing (IDP) techniques, you need a schema for each document class that defines what to extract. But how do you create schemas when you have thousands of documents and don’t know what classes exist? Doing this at scale can take substantial manual effort, making downstream IDP initiatives difficult to justify. In this post, we’ll show you how our multi-document discovery feature solves this problem. It serves as an automated pre-processing step, analyzing unknown documents, clustering them by type, and generating schemas ready for the IDP Accelerator. You’ll learn how the new capability uses visual embeddings for automatic clustering and agents for schema generation. We’ll also walk you through running the solution on your own document collections. IDP Accelerator The IDP Accelerator is a scalable, serverless, open-source solution for automated document processing and information extraction. To customize the solution to your specific document types, it requires a configuration file where you specify the classes and fields. For a minimal configuration example, see the IDP Accelerator GitHub repo. Without a good understanding of your document types, creating this schema can be difficult. The IDP Accelerator includes a Discovery Module that can bootstrap a class configuration from a single example document. However, you must already know your document classes and be able to identify a representative example document for each class. The multi-document discovery feature introduced in this post removes that prerequisite, accelerating your path to applying the IDP Accelerator to a collection of unlabeled documents. Solution overview The following video shows the solution in the IDP Accelerator Console. The multi-document discovery feature automates the transformation of unclassified document collections into structured schemas ready for downstream IDP initiatives. This solution is integrated into the IDP accelerator’s existing Discovery Module. It’s a new “Multiple Document” capability alongside the “Single Document” discovery feature. An AWS Step Functions state machine and AWS Lambda function provide orchestration and serverless compute. The solution processes documents from an Amazon Simple Storage Service (Amazon S3) bucket or Zip file upload. Models available through Amazon Bedrock generate schemas that automatically integrate into the IDP Accelerator configuration file. The following diagram shows the full workflow. The discovery job starts by converting each document in Amazon S3 into a vector embedding using an embedding model available on Amazon Bedrock, then groups similar documents into clusters. An agent built with Strands Agents and an Amazon Bedrock LLM analyzes each cluster to identify the document type and generate a schema. Finally, a reflection step reviews schemas together to catch overlaps and inconsistencies before your final review. Technical details We’ll walk through each step of the process, highlighting key decisions and implementation details. Embedding generation The workflow creates an embedding for each document, converting visual features into numerical representations. For multi-page documents, only the first page is used. Currently, the workflow uses visual embeddings rather than OCR-based text because visual embeddings capture layout, formatting, and structural cues…