AI evals are becoming the new compute bottleneck
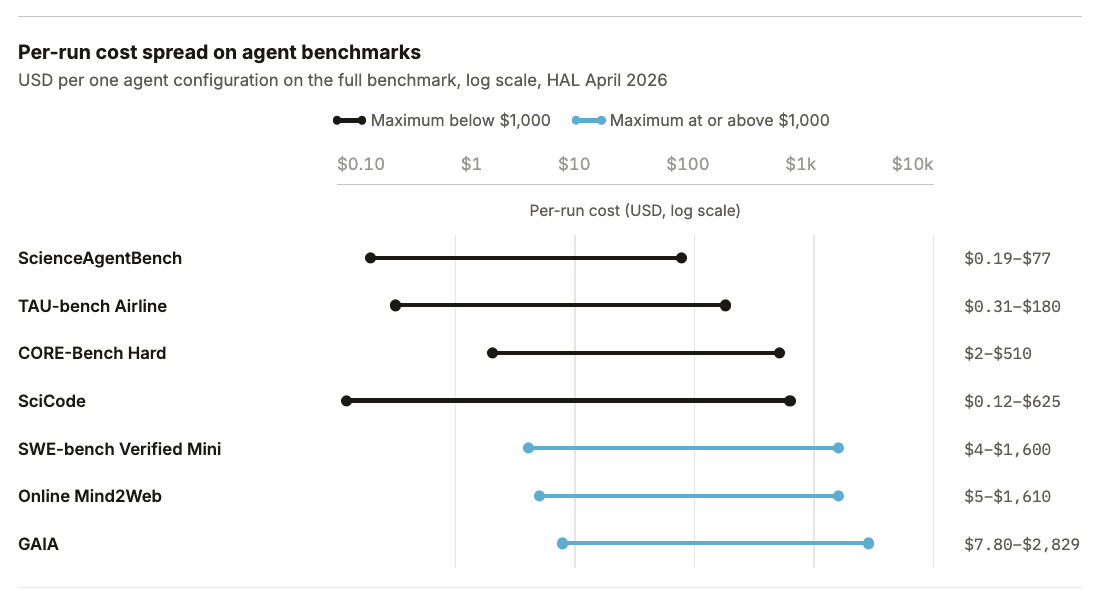
AI evals are becoming the new compute bottleneck Summary. AI evaluation has crossed a cost threshold that changes who can do it. The Holistic Agent Leaderboard (HAL) recently spent about $40,000 to run 21,730 agent rollouts across 9 models and 9 benchmarks. A single GAIA run on a frontier model can cost $2,829 before caching. Exgentic's $22,000 sweep across agent configurations found a 33× cost spread on identical tasks, isolating scaffold choice as a first-order cost driver, and UK-AISI recently scaled agentic steps into the millions to study inference-time compute. In scientific ML, The Well costs about 960 H100-hours to evaluate one new architecture and 3,840 H100-hours for a full four-baseline sweep. While compression techniques have been proposed for static benchmarks, new agent benchmarks are noisy, scaffold-sensitive, and only partly compressible. Training-in-the-loop benchmarks are expensive by construction, and when you try to add reliability to these evals, repeated runs further multiply the cost. Making static LLM benchmarks cheaper The cost problem started before agents. When Stanford's CRFM released HELM in 2022, the paper's own per-model accounting showed API costs ranging from $85 for OpenAI's code-cushman-001 to $10,926 for AI21's J1-Jumbo (178B), and 540 to 4,200 GPU-hours for the open models, with BLOOM (176B) and OPT (175B) at the top end. Perlitz et al. (2023) restate the larger HELM cost pattern, and IBM Research notes that putting Granite-13B through HELM "can consume as many as 1,000 GPU hours." Across HELM's 30 models and 42 scenarios, the aggregate of reported costs and GPU compute came to roughly $100,000. Another shocking observation came from Perlitz et al.'s analysis of EleutherAI's Pythia checkpoints: developers pay for evaluation repeatedly during model development. Pythia released 154 checkpoints for each of 16 models spanning 8 sizes, or 2,464 checkpoints if each model checkpoint is counted separately, so the community could study training dynamics. Running the LM Evaluation Harness across all those checkpoints turns eval into a multiplier on training: Perlitz et al. (2024) noted that evaluation costs "may even surpass those of pretraining when evaluating checkpoints." For small models, evaluation becomes the dominant compute line item across the whole development cycle. When we scale inference-time compute, we scale evaluation costs. Perlitz et al. then asked how much of HELM actually carried the rankings. The result was striking: a 100× to 200× reduction in compute preserved nearly the same ordering, with larger reductions still useful for coarse grouping under the paper's tiered analysis. Flash-HELM turned that finding into a coarse-to-fine procedure: run cheap evaluations first, then spend high-resolution compute only on the top candidates. Much of HELM's compute was confirming rankings that the field could have inferred much more cheaply. Other work reached the same conclusion from different angles. tinyBenchmarks compressed MMLU from 14,000 items to 100 anchor items at about 2% error using Item Response Theory. The Open LLM Leaderboard collapsed from 29,000 examples to 180. Anchor Points showed that as few as 1 to 30 examples could rank-order 87 language-model/prompt pairs on GLUE, and others followed,…