A First Comprehensive Study of TurboQuant: Accuracy and Performance May 11, 2026 · 12 min read TurboQuant, a method for KV-cache quantization, recently gained significant traction in the community due to the large advertised savings in GPU memory from very low bit-width quantization of a...
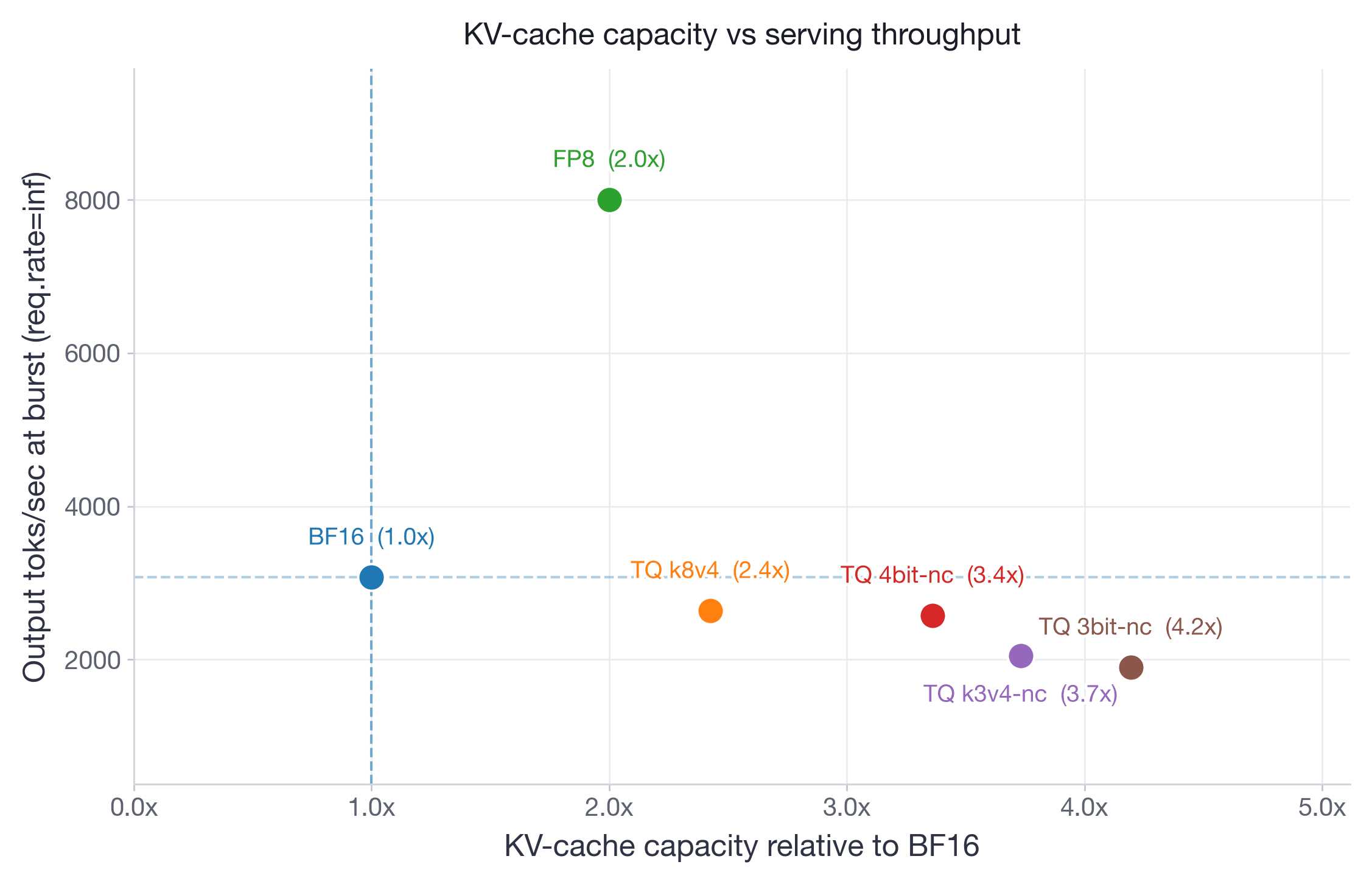
A First Comprehensive Study of TurboQuant: Accuracy and Performance Introduction TurboQuant, a method for KV-cache quantization, recently gained significant traction in the community due to the large advertised savings in GPU memory from very low bit-width quantization of a model's KV-cache. Unlike FP8 KV-cache quantization, which quantizes both the KV-cache storage and the attention computation itself using hardware-native FP8 Tensor Core operations, TurboQuant compresses only the KV-cache storage to 3-4 bits and dequantizes back to BF16 for the attention computation. This architectural difference has significant implications for both accuracy and performance. However, most of the reported results were based on small models evaluated on short-context benchmarks that do not stress-test KV-cache quantization. To provide the community with more actionable data, we conducted a comprehensive study spanning four models (both decoder-only and MoEs), from 30B to 200B+ parameters, and five benchmarks including both prefill-heavy long-context retrieval and decode-heavy reasoning workloads. TL;DR - FP8 via --kv-cache-dtype fp8 remains the best default for KV-cache quantization: it provides 2x KV-cache capacity with negligible accuracy loss, while matching BF16 on most performance metrics and substantially improving them in memory-constrained serving scenarios. - TurboQuant k8v4 does not provide any significant advantage over FP8: it only provides modest KV-cache savings (2.4x vs 2x) which are not worth the consistent negative impact on throughput and latency metrics. - TurboQuant 4bit-nc is likely the most practical TurboQuant variant: it helps under KV-cache memory pressure, but trades the extra capacity for moderate accuracy, latency, and throughput costs. It may still be viable for edge deployments where memory is the dominant constraint. - TurboQuant k3v4-nc and3bit-nc show meaningful accuracy drops, especially on reasoning and very long-context tasks, while also substantially degrading latency and throughput. This makes them poor candidates for production deployments. Table of Contents Quick start: Experimental Setup Quantization Schemes: We benchmark four TurboQuant variants (--kv-cache-dtype turboquant_{k8v4, 4bit_nc, k3v4_nc, 3bit_nc} ) against unquantized BF16 and FP8 KV-cache baselines. turboquant_k8v4 uses 8-bit keys and 4-bit values; turboquant_4bit_nc uses 4-bit keys and values with norm correction; turboquant_k3v4_nc uses 3-bit keys and 4-bit values with norm correction; and turboquant_3bit_nc uses 3-bit keys and values with norm correction. The FP8 baseline (--kv-cache-dtype fp8 ) stores queries, keys, and values in FP8 precision, and also quantizes the attention computation itself — a key difference from TurboQuant, which only compresses storage. For more details on each TurboQuant variant, please refer to the paper and vLLM documentation. For more details on FP8 KV-cache quantization, please refer to the FP8 KV-cache blog post. Benchmarks: We evaluate on five benchmarks designed to stress-test KV-cache quantization across both prefill-heavy and decode-heavy workloads. For long-context retrieval (prefill-heavy), we use openai/mrcr — a challenging multi-round context retrieval task testing sequence lengths up to each model's maximum supported length. For reasoning (decode-heavy), we use AIME25, GPQA:Diamond, MATH500, and LiveCodeBench-v6. All evaluations adopt the default non-greedy sampling parameters suggested by model creators to mimic real-world deployment. Models: We focus on four models spanning both small and large scale, and both decoder-only and MoE architectures:…