4/6/2026 Own Your AI: Fireworks Training Preview
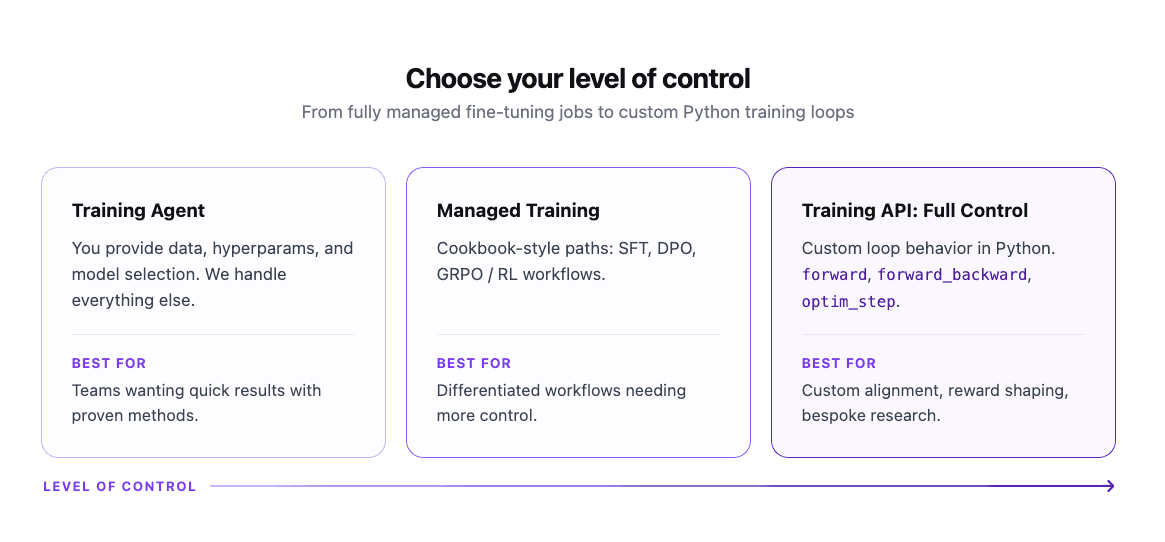
Fireworks Training is now in preview: an end-to-end platform for training and deploying frontier models at scale. Three surfaces for three kinds of teams, from a conversational agent that handles everything, to managed infrastructure for ML engineers, to bring-your-own training loop on Fireworks-hosted clusters. All on the same infrastructure that already handles production inference for Cursor, Vercel, Genspark, and others. All three surfaces are in preview now. Reinforcement learning is how teams push past the ceiling SFT hits on multi-step reasoning, reliable tool use, and mid-flight self-correction. Vercel used our RL infrastructure to build a custom "Auto Fix" model for v0. The model checks the output stream for errors and self-corrects without a second pass, reaching a 93% error-free generation rate, significantly outperforming closed frontier models, with a 40X improvement in end-to-end latency vs. the proprietary model it replaced and over 8,000 characters per second throughput. "Using a fine-tuned reinforcement learning model with Fireworks, we perform substantially better than SOTA. In our evaluation, Sonnet 3.5 compiled at 62%, and we got our error-free generation rate well into the 90s." — Malte Ubl, CTO at Vercel Genspark applied frontier RL to Kimi K2, a 1 trillion parameter open-source model, for deep research agents requiring multi-source investigation and chained tool calls. The RL-trained model unlocked a 33% increase in tool calls, surpassing a state-of-the-art closed model at 50% lower cost. "Fireworks enabled us to own our AI journey, and unlock better quality in just four weeks." — Kay Zhu, CTO at Genspark Cursor ran RL rollouts for Composer 2 (now top-scoring on CursorBench) across 3 to 4 clusters worldwide, with training and production traffic sharing the same GPU pool via delta-compressed weight updates. Frontier RL doesn't require one mega-cluster. The assumption that you need co-located RDMA hardware rests on moving a full 1 TB checkpoint on every update. You don't. "Our RL inference scales elastically and globally because of it. When we have low prod traffic we scale up RL, when we have high prod traffic, we scale down RL." — Federico Cassano, Research at Cursor RL gets the headlines, but the truth is most teams start their fine-tuning journey with SFT and the gains are immediate. The most common pushback we hear is that closed models are "good enough." On a customer support dataset, a fine-tuned Qwen3 8B Instruct model hits an F1 score of 76.38% vs 69.40% on leading closed source model. In fact Qwen3 0.6B, 4B, and 30B all outperform the closed model on this benchmark, at significantly lower cost. On a production customer operations dataset, fine-tuned Qwen3 30B reaches 91.71% versus the closed model's 82.48%. On a ticket routing task, fine-tuned Qwen3 30B reaches 80.91%, a 19-point gap over Claude Haiku (61.47%) and 9 points over Gemini Flash (71.93%). Fine-tuned Qwen3 models at every size beat or match Gemini Flash, produce zero invalid outputs (versus 15% for Claude Haiku), and run 2.5–20X faster at p50–p95 latency. For tasks where correctness is hard to label but preference is easy…
