Training and Finetuning Multimodal Embedding & Reranker Models with Sentence Transformers

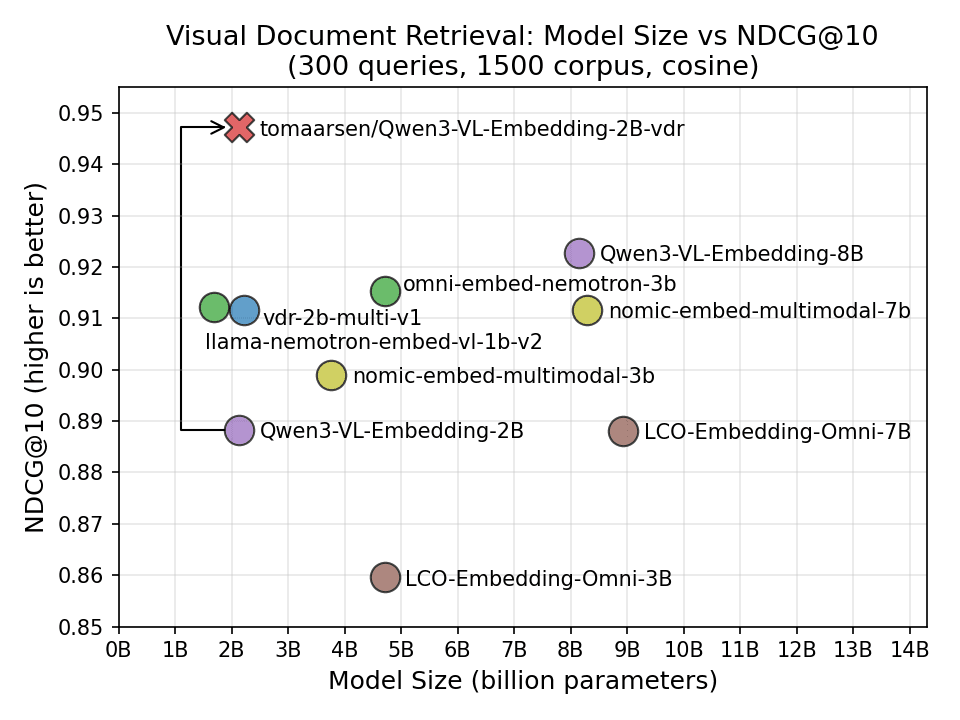
Training and Finetuning Multimodal Embedding & Reranker Models with Sentence Transformers As a practical example, I'll walk through finetuning Qwen/Qwen3-VL-Embedding-2B for Visual Document Retrieval (VDR), the task of retrieving relevant document pages (as images, with charts, tables, and layout intact) for a given text query. The resulting tomaarsen/Qwen3-VL-Embedding-2B-vdr demonstrates how much performance you can gain by finetuning on your own domain. On my evaluation data, the finetuned model achieves an NDCG@10 of 0.947 compared to the base model's 0.888, and outperforms all existing VDR models I tested against, including models up to 4x its size. If you're new to multimodal models in Sentence Transformers, I recommend reading Multimodal Embedding & Reranker Models with Sentence Transformers first. For training text-only embedding, reranker, or sparse embedding models, see the Prior Blogposts section at the end. Table of Contents - Why Finetune? - Training Components - Model - Dataset - Loss Function - Training Arguments - Evaluator - Trainer - Results - Training Multimodal Reranker Models - Additional Resources Why Finetune? General-purpose multimodal embedding models like Qwen/Qwen3-VL-Embedding-2B are trained on diverse data to perform well across a wide range of languages and tasks: image-text matching, visual question answering, document understanding, and more. But this generality means the model is rarely the best choice for any specific task. Consider Visual Document Retrieval: given a text query like "What was the company's Q3 revenue?", the model must find the most relevant document screenshot from a corpus of thousands. This requires understanding document layouts, charts, tables, and text, which is a very different skill from e.g. matching pictures of shoes with product descriptions. By finetuning on domain-specific data, the model can learn these specialized patterns. In my experiment, finetuning improved NDCG@10 from 0.888 to 0.947, ahead of every recent multimodal model I tested, including ones up to 4x larger. Training Components Training multimodal Sentence Transformer models involves the same components as training text-only models: - Model: The multimodal model to train or finetune. - Dataset: The data used for training and evaluation. - Loss Function: A function that quantifies the model's performance and guides the optimization process. - Training Arguments (optional): Parameters that influence training performance and tracking/debugging. - Evaluator (optional): A tool for evaluating the model before, during, or after training. - Trainer: Brings together the model, dataset, loss function, and other components for training. The multimodal training pipeline uses the same SentenceTransformerTrainer as text-only training. The key difference is that your datasets contain images (or other modalities) alongside text, and the model's processor handles the image preprocessing automatically. Let's walk through each component, using Visual Document Retrieval (matching text queries to document screenshots) as a running example. Model The most common approach is to finetune an existing multimodal embedding model, or to start from a Vision-Language Model (VLM) checkpoint. The Transformer module automatically detects supported modalities from the model's processor. To finetune an existing multimodal embedding model (e.g. one that already has a modules.json file), you can pass processor_kwargs and model_kwargs to control preprocessing…