The PR you would have opened yourself

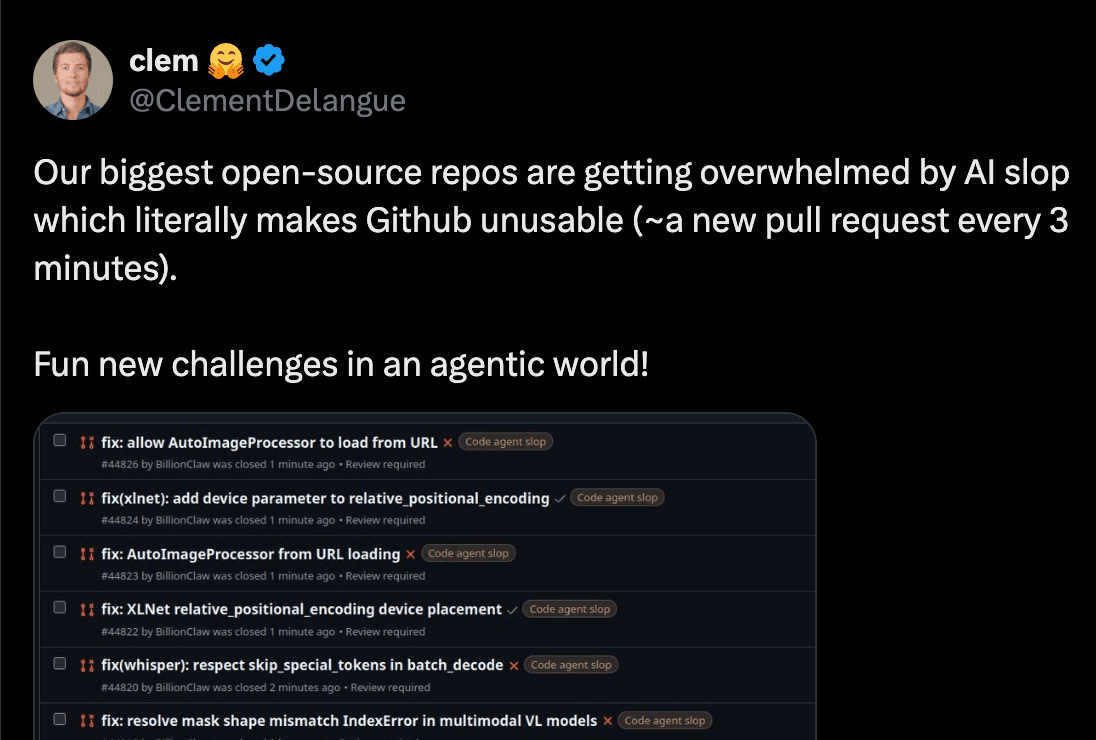
The PR you would have opened yourself TL;DR We provide a Skill and a test harness to help port language models from transformers to mlx-lm, so they become (almost) instantly available the moment they are added to transformers. The Skill is designed to support contributors and reviewers as an aide, not an automation. We explain why we did it, how, and comment about how to meaningfully contribute to open source in the age of agents. The advent of code agents In 2026, code agents started to actually work. What used to be auto-completion at the side of your editor turned into a system that one-shots reasonable solutions from brief specifications. The generated code usually works out of the box, covers what you asked for, and makes reasonable assumptions about details you didn't specify. This is great. As Jensen Huang puts it, we've instantly gone from 30 million to one billion coders in the world. Creative minds are unleashed. But it forces us to rethink open source. Take the transformers library as an example. It has hundreds of contributors, is used in thousands of projects, has been downloaded over a billion times. Suddenly, anyone with an agent can instruct it to find some open issue, fix it, and submit a PR. And that's exactly what's happening. Those people feel happy because they are contributing to a great library, but the sad reality is that, most of the time, they don't realize they are not. Why not? There are two assumptions that agent-generated PRs usually miss. Codebases like transformers care deeply about the code. It's cool to build projects where it doesn't matter what the code looks like, but transformers is not one of them. Being used by thousands of people, transformers is primarily built as a human-to-human communication method, through code. Model files read top to bottom, because we want practitioners to understand them without jumping through complex abstractions. This permeates throughout the library design and is the reason why, for example, we favor flat hierarchies. Agents don't have that context. Because design decisions are not explicit, agents suggest refactors to "improve" the codebase by following "best practices", without realizing they are breaking implicit contracts between the library and its users. They are verbose, generalize too early, don't notice when a change affects other areas, introduce subtle bugs, break performance. They are also sycophantic, and accept any idea as good and follow it through diligently, including ones a maintainer would have pushed back early on with a terse comment. A small number of maintainers still has to read every PR, understand it, decide if the design direction is right, identify side effects, and write feedback. PR volume has gone up tenfold, but the amount of maintainers has not (and cannot, because team coordination does not scale). What does this have to do with MLX? Transformers is one of the first projects to feel this pressure because of sheer volume, but the same dynamic is happening everywhere. As an example from a…