Introducing NVIDIA Nemotron 3 Nano Omni: Long-Context Multimodal Intelligence for Documents, Audio and Video Agents

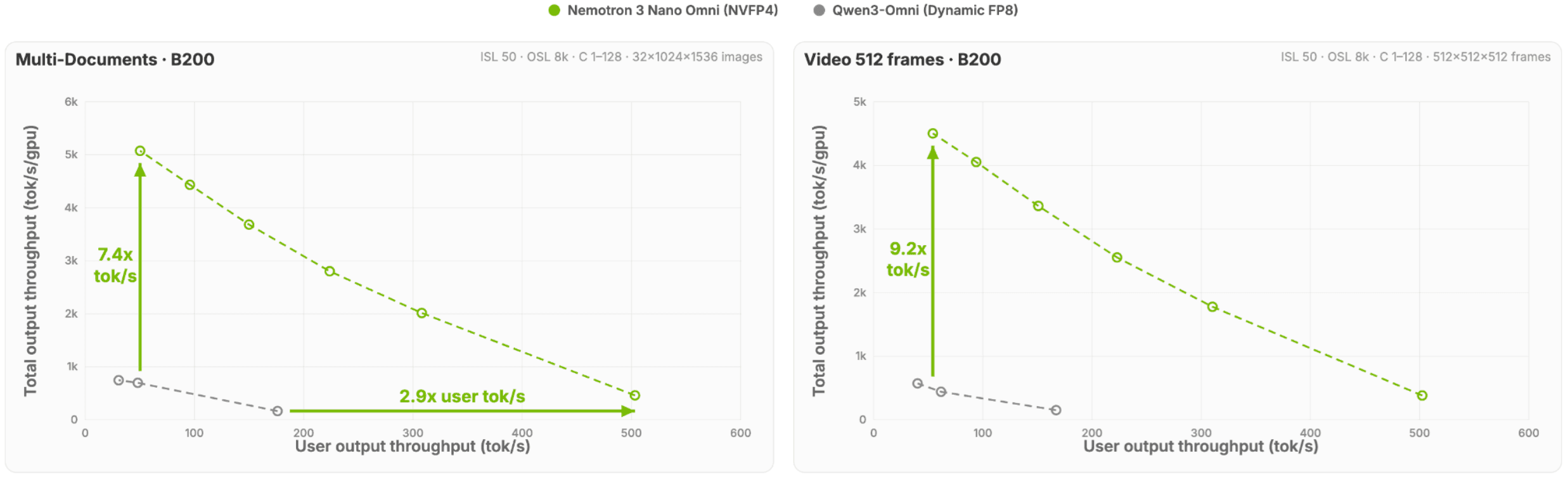
Introducing NVIDIA Nemotron 3 Nano Omni: Long-Context Multimodal Intelligence for Documents, Audio and Video Agents - NVIDIA Nemotron 3 Nano Omni is a new omni-modal understanding model built for real-world document analysis, multiple image reasoning, automatic speech recognition, long audio-video understanding, agentic computer use, and general reasoning. - It extends the Nemotron multimodal line from a strong vision-language system to a broader text + image + video + audio model. - Nemotron 3 Nano Omni delivers best-in-class accuracy on complex document intelligence leaderboards such as MMlongbench-Doc, OCRBenchV2, while also leading in video and audio leaderboards like WorldSense and DailyOmni. It achieves top accuracy on VoiceBench for audio understanding and ranks as the most cost‑efficient open video understanding model on MediaPerf. - Under the hood, it combines the Nemotron 3 hybrid Mamba-Transformer Mixture-of-Experts backbone with a C-RADIOv4-H vision encoder and Parakeet-TDT-0.6B-v2 audio encoder. - The architecture is designed to preserve fine visual detail, add native audio understanding, and scale to very long multimodal contexts for dense images, documents, videos, and mixed-modality reasoning. - The training recipe uses staged multimodal alignment and context extension, followed by preference optimization and multimodal reinforcement learning. - Nemotron 3 Nano Omni delivers up to 9x higher throughput and 2.9x the single-stream reasoning speed on multimodal use-cases, compared to alternatives. - Download the BF16, FP8 and NVFP4 checkpoints at HuggingFace. - For more information about the model architecture, training recipe, data pipelines and benchmarks, read the full Nemotron 3 Nano Omni report. Building on Nemotron Nano V2 VL, Nemotron 3 Nano Omni delivers substantial visual gains and adds entirely new audio and video+audio capabilities - while also leading another open-weights omni model, Qwen3-Omni, in many domains. Efficiency highlights Compared to other open omni models with the same interactivity, Nemotron 3 Nano Omni delivers 7.4x higher system efficiency for multi-document use cases and 9.2x higher system efficiency for video use cases Figure 1. Total system throughput for multi-document and video use cases sustained by each model at a fixed per‑user interactivity threshold (tokens/sec/user) What Nemotron 3 Nano Omni is designed for At a high level, Nemotron 3 Nano Omni is aimed at five classes of workloads: 1. Real-world document analysis This is not only about OCR. The model is positioned for long, messy, high-value documents where understanding depends on layout, tables, figures, formulas, section structure, and cross-page references. Think contracts, technical papers, reports, manuals, multi-page forms, or compliance packets. The model can handle 100+ page documents. 2. Automatic Speech Recognition Nemotron 3 Nano Omni includes strong speech understanding capabilities that enable high-quality transcription across diverse audio conditions. It handles long-form audio with varying speakers, accents, and background noise. These capabilities can be integrated into broader workflows, allowing spoken content to be transcribed, analyzed, and combined with other modalities for tasks like summarization, question answering, and cross-modal reasoning. 3. Long audio-video understanding Many enterprise and developer workflows depend on mixed audio and visual evidence: screen recordings with narration, training videos, meetings with slides, tutorials, product demos, customer support captures,…