Build custom code-based evaluators in Amazon Bedrock AgentCore

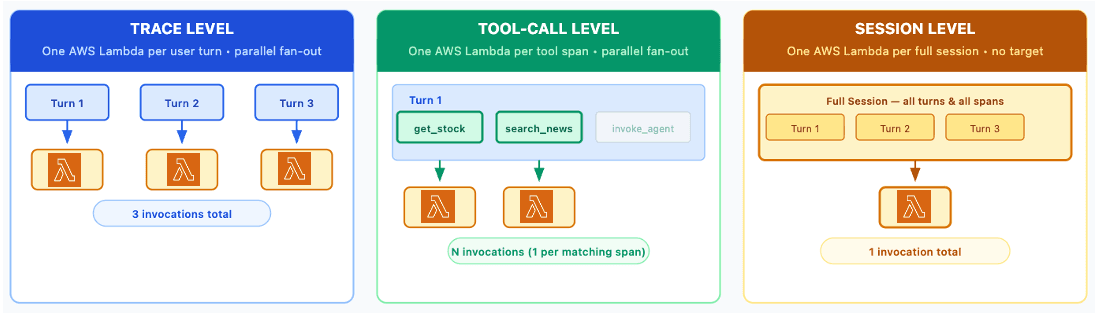
Artificial Intelligence Build custom code-based evaluators in Amazon Bedrock AgentCore Special thanks to everyone who contributed to this launch: Stephanie Yuan, Lefan Zhang, Ritvika Pillai, Irene Wang, Carter Williams, T.J Ariyawansa, Gitika Jha, Shoaib Javed and the product leadership from Vivek Singh. Moving prototype agents to production requires measuring quality across multiple dimensions. Amazon Bedrock AgentCore Evaluations provides large language model (LLM)-as-a-Judge checks and extensible code-based evaluators that capture domain-specific requirements you need for assessing your agentic application. In financial services and specialized domains, the critical quality dimensions often extend beyond language. A market-intelligence agent must quote stock prices within a configurable live band, follow a mandatory broker-identification workflow before accessing financial profiles, return tool outputs that conform to a strict JSON schema, and withhold personally identifiable information (PII). These checks require deterministic code that produces the same result on identical input. They can also be expensive to run with LLM-as-a-Judge when an objective piece of code is the straightforward choice. With custom code-based evaluators, you can bring an AWS Lambda function as the evaluation engine. With custom code-based evaluators, you control the scoring logic: regex and structural validation, external data lookups, calls to other services, or business rules. The same evaluator can be used in multiple ways without requiring foundation model (FM) tokens for each request. In on-demand evaluations, it acts as a gate within development workflows and continuous integration and delivery (CI/CD) pipelines. In online evaluation setups, it can score live production traffic. With full control over the evaluation logic through AWS Lambda, you can tailor custom code-based evaluators to your needs. Even if traces come from different agent frameworks, you can use this approach to consistently assess agent quality using your own logic. In this post, you will implement four Lambda-based custom code evaluators for a financial market-intelligence agent, register each with AgentCore, and run them in on-demand and online modes. You will also see how to combine custom code-based evaluators with built-in evaluators and how to call other AWS services for grounded fact-checking, PII detection, and real-time alerting. Quality dimensions suited to code-based evaluation Agents depend on structured tool outputs like JSON from search, retrieval, or business APIs. A contract change, parsing bug, or upstream outage can produce malformed data that the agent weaves into a wrong answer. Tool response schema validation catches structural issues at the tool boundary and is well suited as a code-based check, while LLM-as-a-Judge evaluators complement it to judge usefulness and clarity. Agents quote prices, metrics, thresholds, and quotas, and deviations as small as 0.1 percent can change a financial trading decision. LLMs are prone to arithmetic errors, while a code-based evaluator calls the reference system, computes the tolerance, and flags each discrepancy. Numerical accuracy against a reference source is most effectively verified deterministically. Agents operating under ordering and policy constraints should identify the user before reading sensitive data, capture approvals before executing actions, and follow a specific tool sequence to maintain data integrity. Verifying workflow contract compliance requires inspecting the…