3/28/2026 The Fine-Tuning Bottleneck Isn't the Algorithm
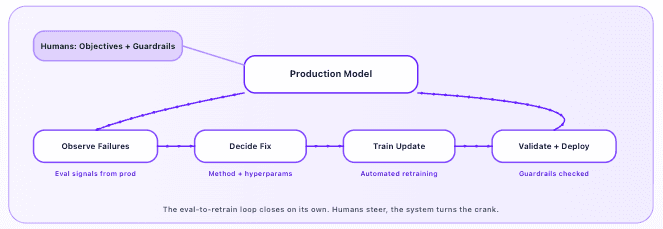
TL;DR: Integration friction and slow iteration cycles are the bottlenecks that actually stall fine-tuning — not the algorithm. We share the patterns we see across engagements, how teams like Cursor and Genspark broke through them, and where the workflow is heading: toward fully agentic fine-tuning loops that close themselves. Most teams that come to us for fine-tuning are not struggling with the training algorithm. They are struggling with everything around it: getting reward functions to talk to internal APIs without leaking data, waiting days between experiments because each step lives in a different tool, and figuring out whether the problem even calls for SFT, RFT, or DPO. Over the past year, working with a select group of the most innovative startups, digital natives, and Fortune 500 companies, we have seen these patterns repeat across every engagement. Every team that comes to us for fine-tuning is building a domain-specific agent. Code fixing, customer support, deep research, financial operations — the use case differs but the shape is the same. A generic frontier model hits a quality ceiling and the path forward is model-level customization. The ceiling is concrete. Genspark's Deep Research agent was stuck at a 0.76 reward score on closed frontier models. They moved to RFT on open models via Fireworks and pushed past 0.82 — a jump that prompt engineering alone could not deliver. One large digital native company we worked with saw a 30% increase in task quality and a 2.5x reduction in latency after fine-tuning with RFT. Prompt engineering can only get you so far, to reach a new capability tier you need fine tuning. Within a single account, we saw use cases ranging from escalation detection to reward modeling to AI-powered search — all running concurrently. That breadth inside one organization tells you fine-tuning is ongoing infrastructure for building agentic systems, not something you do once and move on from. Every team follows the same arc: a generic model hits a quality ceiling, fine-tuning closes the gap, and the result is a domain-specific agent in production. Across these engagements — different industries, model sizes, use cases — the same problems keep coming back. The interesting thing is that none of them are about the training algorithm itself. They are all about what surrounds it. The most consistent blocker is integration. Reward functions, internal graders, and evaluation APIs have to stay inside the customer's environment. Sensitive business logic and proprietary data cannot leave for third-party scoring. Fireworks addresses this at two levels. For teams that need full data isolation, Training API lets you run training loops where the data never leaves your environment — you control the Python process, the data stays on your side, and only weight updates flow through the platform. For managed fine-tuning, secure bring-your-own-bucket storage and remote environments keep evaluators executing inside the customer's VPC. One team was constrained to specific non-Chinese open-source models for compliance. Model availability and geopolitical requirements shape the fine-tuning workflow just as much as the training algorithm does.…
